An Identity domain is a scope within which we consider it a given that the user has a shared or trivially joinable identity.
This is a privacy boundary, not a security boundary. Hence it assumes that where possible all sites share information.
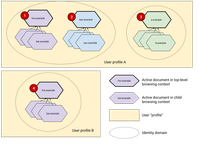
Above is a diagram showing relationships between clusters of documents and identity domains.
-
foo.exampleandbaz.examplebelong to the same first party set. -
a.examplehas no first-party relationship with any other domain.
The Identity domain has the following properties:
-
All active documents in descendent browsing contexts belong to the same identity domain as the active document in the top-level browsing context.
See each cluster of browsing contexts in the diagram above.
-
All active documents in top-level browsing contexts that share the same site also share the same identity domain.
In the diagram above,
foo.examplein cluster 1 andbaz.examplein cluster 2 belong to the same first-party set, hence they are considered to belong to the same identity domain. Howevera.examplein cluster 3 does not belong to the same identity domain because there’s no first party relation betweena.exampleand any other top level domain in the diagram. -
All private client state including but not limited to open sockets, socket pools, cookies, storage, permissions / content settings, transient caches of credentials, cached resources, service workers, and shared workers accessible to any document in an identity domain also belong to the identity domain.
-
Identity domains don’t span browser profiles.
See clusters 1 and 4 in the diagram above. Both share top-level origins, but don’t share identity domains because they are in two different browser profiles.
-
Identity domains don’t span browsers.
Derived from above.
-
Identity domains don’t survive browsing data erasures.
Erasing an identity domain – and thus an identity – requires destroying all private client state mentioned previously. Hence erasing an identity domain involves discarding all
Documentobjects and workers in that identity domain.
Note that in the existing web privacy model third-parties can trivially associate identities across top-level contexts. Thus the entire internet essentially amalgamates into a single identity domain.
The boundaries discussed herein require moving to a different model of identity on the web. The privacy threat model guiding this model is discussed in PING’s Target Privacy Threat Model document which is a work in progress as of this writing.
Additional Notes and Observations
-
The identity domain is a privacy boundary. The boundary is something that’s asserted by the user-agent and doesn’t depend on the cooperation of sites. I.e. assumes that sites involved are worst case actors.
- Not to be confused with security boundaries like those imposed via Content Security Policy.
-
The definition assumes that sites can share information out-of-band. The identity domain boundary does not require sites to cooperate.
-
The same site can appear in multiple identity domains. For example, re-identification is equivalent to a single site joining an identity across disjoint domains.
One can also imagine a user-agent that maintains multiple identity boundaries for the same top-level site for the purpose of allowing multiple sets of cookies to be used from the same device.
-
Two identity domains can be joined by sharing a unique identifier between the two domains.
-
WRT federated identity (as detailed in WebID) multiple relying parties join identity domains by virtue of shared unique identifiers like email address. Similarly identity providers can also generate and use unique identifiers linking domains.
We likely need another term for describing externally joined identity domains. In such cases the UA doesn’t necessarily know or can prevent joining of identity domains.
-
-
Concepts like “logging out” can be defined in terms of destroying an identity domain on the User Agent.