
From Here To There On The Internet
Devices on the internet including your phone, laptop, gaming console, refridgerator, etc. communicate by exchanging data “packets”. They are of course not physical packets. It’s just a useful way to describe a unit of data sent over a wire or some other network connection. A packet could be thought of as, say, a single frame in a video or a small slice of audio, or a couple of paragraphs of text in a webpage. Devices on the internet will take a big chunk of data (e.g. a video clip) and break it down into smaller pieces (e.g. a single frame in the video clip) and then sends each of these pieces along the network. The receiving device puts the pieces back together to reconstruct the original thing (e.g. the video clip again)1.
Each packet has little pieces of extra information to help it get to where it needs to go. One piece is where it comes from (a source “address”). Another is where it is going (a target “address”). Devices along the network (like your internet provider’s networking equipment, satellites, etc.) use this extra information to correctly route the packets to their intended destination.
The network is large and constantly changing. So each device focuses only on getting the packet at least one step closer to its destination. The specific journey taken by a packet is unkonwn until it is on its way.
Faster and Faster
So let’s say a video streaming service wants to send your mobile phone a video. First the streaming service breaks up the video into small packets. Then it throws all the packets into the network so that the network can deliver them to your phone.
If the streaming service pushes data out at exactly the right speed and the network doesn’t break, then everything works out great. All the packets make it to the destination without hassle. But neither the streaming service nor your phone know what that right speed is due to the aforementioned unknowability of the network.
Sending too much data can overwhelm some devices or connections in the network. If a device gets more data than it can handle, it’s likely that it will start dropping packets until it can catch up.
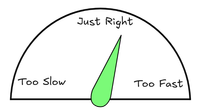
Sending too little data isn’t great either. The speed might be too slow for streaming video. The receiving device will underperform. Users will be confused why their expensive broadband connection doesn’t let them watch streaming video.
So how does the device know how much data to send out?
Flow Control
The mechanisms we use to regulate the flow of data is called “flow control.” We are going to look at a method based on coordination between the sender and the receiver because they are the only two actors in this scenario that we consider to be reliable and stable.
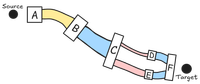
Different packets can take different paths See the network connections
between C-D and C-E in the diagram above.
Either of these paths can take a packet from C to
F. Packets going down different paths will arrive at
different times. Also, if the network gets overwhelmed or breaks, then
some of the packets may not make it at all.
The reciever needs to know how to put the packets back in order and tell if any are missing.
To keep track of which packet is which, we can add some new information to the data packet: let’s call this the sequence. As you might imagine, the sequence can start at 1 and count each packet until the transmission is over. Each packet now has a unique position in the list of packets.
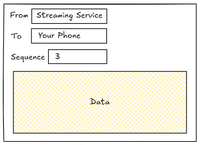
Great. But how do we know which packets made it to the other side? The recipient will need to let us know this information in some sort of reply. This reply is also a data packet called an acknowledgement. It’s sent from the original recipient back to the sender.
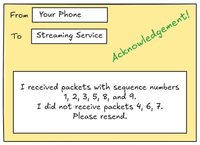
Ok so now we have all the information we need to perform some flow control.
We can now figure out the optimal rate of data transfer experimentally using some method like this:
- Send data as fast as possible.
- If the recipient claims some packets were missing, then resend those packets and send packets slower than before.
- If the recipient hasn’t complained of missing packets in a while, try sending them faster.
Stuck On The Wire
Now imagine you sending data out - a rate of 100 packets per second. And let’s say it takes one second for a packet to get to the other side. Just before the end of the first second, the destination hasn’t received the first packet yet. But the sender has sent 100 packets.
Where are the packets?
We call this “data on the wire’. Some data is indeed on the wire literally, but that tends to be a tiny amount. Most of the data on the wire is actually at each of the devices along the way either being received, or waiting to be sent.
So once we factor in the equipment in the middle, your path to the destination looks a little like this:
The device sees some data come in, stores it, figures out where to send it next, and sends it on its way. There could be other stuff these boxes could be doing, but that’s something for another post.
So from the perspective of a single box the world looks a bit like this:
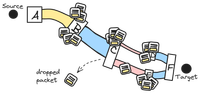
If this is the limit for the network and the sender keeps sending more packets, then there’s no room for the packet. So it gets “dropped”.
It is common for a device to be at the border of a “good” network and a “not”good” network. The goodness here is the amount of data that can be stuffed into it.
When a burst of data comes along, not much data can be stuffed into the small pipe before no more can fit.
As mentioned before, this means that the sender will need to re-send the dropped packets and also slow down the rate of data. Given enough time the rate of data transfer will approach the throughput of the smallest pipe along the way.
Buffer Bloat
Some folks looked at this setup and decided to improve things. There are some valid reasons for doing what they did – which is why so many people did this. But it didn’t quite have the intended effect.
So, what was the thing they did? They added buffering. Too much of it.
A buffer is a resevoir where excess packets can be kept until the next link in the network is ready to accept more. What this means is that every device along the way is trying to do flow control by storing and resending packets instead of letting the sender know that packets are getting dropped.
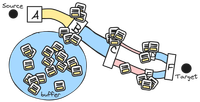
As before, let’s say the sender is sending 200 packets every second. The network still can only transfer 100. The excess packets – another 100 of them – gets tossed into the buffer.
What happens just one second later?
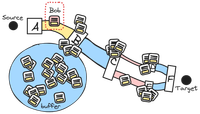
The very next packet – let’s call it Bob – that the sender
tosses into the network will end up in the buffer since B
is still waiting for some of the first 100 packets to get past
C.
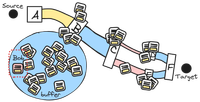
Bob is the last packet in the buffer and must wait for all the other packets in the buffer to be send before it will get queued to sent out.
In another second, the first 100 packets make it to the target, and now the 100 packets that were in the buffer are back on the wire.
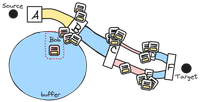
Bob is still in the buffer but it’s the next one in line to get back on the network.
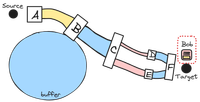
Once back on the network it will take another second for Bob to reach the target.
Even under ideal conditions eventually the system settles on a new equilibrium with one difference.
The length of time it takes for the data packets to make their way to the destination is much larger. Packets accumulate in buffers along the network. Each buffer adds an additional delay for the packet.
Overall the throughput of the network is the same. But latency – the time it takes for a packet to get to the destination – is much larger.
The effect is even worse in practice because this setup resists any attempt at flow control. It delays the discovery of actual throughput.
This phenomenon is called buffer bloat.
-
This is obviously a massive oversimplification. But doesn’t change the thesis presented next.arrow_upward